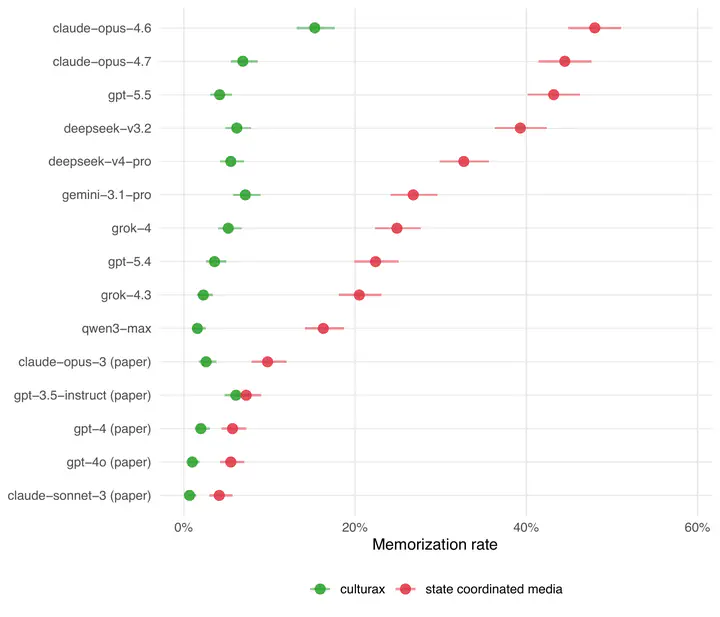
 Memorization rates across paper-era and current-generation LLMs. State-coordinated media phrases in red, general CulturaX web text in green. Newer models complete the held-out half of each phrase at substantially higher rates than the paper-era models.
Memorization rates across paper-era and current-generation LLMs. State-coordinated media phrases in red, general CulturaX web text in green. Newer models complete the held-out half of each phrase at substantially higher rates than the paper-era models.
Hannah Waight, Eddie Yang, Yin Yuan, Molly Roberts, Brandon Stewart, Josh Tucker and I published a paper in Nature (2026) showing that state-controlled media in LLM training data influences how those models talk about politics.
But we ran those audits in 2023-2024–it took a long time to get the paper published!
We wanted to know what happens with the current generation of models, especially re how models memorize state media talking points, and I’d seen a lot of criticism of LLM papers that relied on legacy generation models recently on Twitter. I also wanted to show what being more pro-regime looks like in the actual text.
And you don’t land a Nature paper every day!
Now in the past, this is the kind of thing that I would get excited about but never actually execute because there’s a lot of slow and boring scaffolding work outside my expertise required to set this up. But I started using Claude Code late last year and of course CLI-AI tools are great for stuff like this.
In fact, Josh and I recently wrote a piece in Brookings about how agentic AI might make it possible to do more public outreach like this.
So I built an interactive companion site that replicates the core studies from the paper on current-generation models. The whole team gave feedback and what came out was pretty cool. It looked great and a few new and important findings emerged from the effort.
By and large, the core findings hold. In 38 countries, where more than 70% of langauge speakers reside, there’s a strong negative correlation between press freedom and pro-government LLM valence (-0.89) relative to English in current-generation models. Every current-generation model still produces more pro-government answers in Chinese than in English about Chinese leaders and institutions. Memorization rates for state-coordinated media phrases continue to be at or above rates for general web text.
Two years of capability improvements and safety work have not changed the underlying issue.
The highlights
-
Memorization effects are far larger for new models. As expected, newer larger models memorize state media-aligned text a much higher rates than do the models we tested in the paper. We prompted models with the first half of 2,000 distinctive phrases and measured how often each model completes the second half of the phrase nearly perfectly. Half of the phrases are from Chinese state media talking points (red) and half from general Chinese web text (green/blue).
-
Newer models tend to be even more positive toward China in Chinese.
DeepSeek V4 Pro is overwhelmingly pro-China in both languages. Spot-checking suggests it’s spouting state media talking points in English: “principles of socialism with Chinese characteristics” and “whole-process people’s democracy.” To examine DeepSeek’s pro-China valence relative to other models, I ran pairwise llm-as-judge comparisons across nine current-generation models holding language constant and fit a Bradley-Terry model. DeepSeek V4 Pro ranks first on China-favorability in both English and Chinese.
Code and data: github.com/state-media-influence-llm/replication
Paper: Waight et al. 2026, Nature (complimentary copy)
Companion site: state-media-influence-llm.github.io
Sol Messing
Researcher
Sol Messing is Researcher at Google DeepMind and Research Associate Professor at New York University