On January 17, 2020 my team at Facebook launched one of the largest social science data sets ever constructed. It’s meant to facilitate research on misinformation from across the web, shared and spread on Facebook.
Full details on the release here.
We also released the URL santization framework, which I implemented (and which my SWE colleagues refactored).
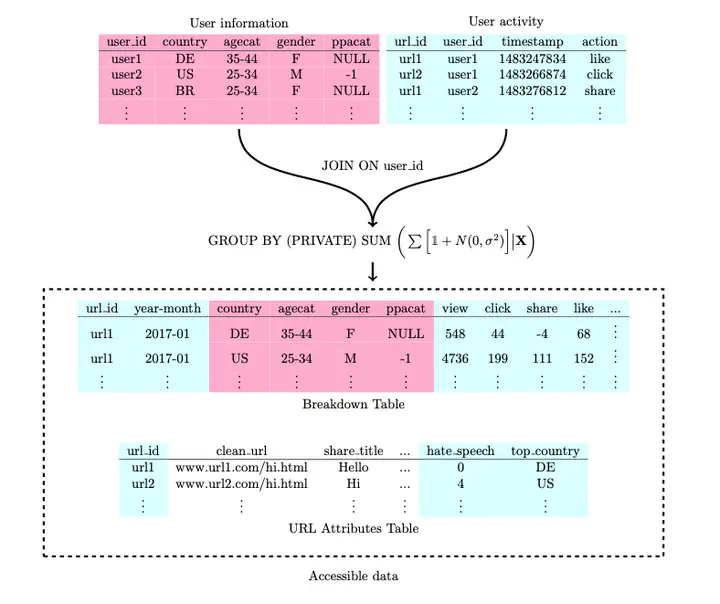
What makes this data release unprecedented is that it contains exposure data describing external links that billions of users saw and read while using the site.
The data set goes beyond URL-level data, breaking down exposure and interactions by month, country, age, gender, and in the U.S., political page affinity (see Barbera et al 2015).
The data contain two tables: (1) a “URL attributes” table describing the 38 million URLs in the data set, including how many times users tagged those posts as containing misinformation, harassment, etc. and (2) a “breakdown” table, which aggregates counts of actions taken on urls, broken out by user demographics and URL attributes.
The technical documentation reflects more work than most papers I’ve written: . This list of authors reflects the scale of this massive team effort, and that’s before you include increadibly helpful advice we got from a number of computer scientists in the academy listed in the acknowledgements.
Perhaps most importantly, this release provides guarantees about anonymity in an incredibly rigorous way–action-level differential privacy, while preserving more underlying signal in the data.
Sol Messing
Research Associate Professor
Sol Messing is Research Associate Professor at New York University